
Dziedzictwo: piekło czy okazja?



- AKT 1 (Nie)spodziewana podróż – wprowadzenie.
- Notka autora.
- Świat menedżerów ETF.
- Nasza (nie)oczekiwana podróż.
- AKT 2 Spustoszenie migracji – pierwsze migracje małych mikroserwisów.
- Konfiguracja wstępna.
- JBoss świadczył usługi.
- Starszy kod zależny od JNDI.
- AKT 3 Wielka bitwa – główna migracja monolitu.
- Czyszczenie konfiguracji.
- Zarządzanie hasłami
- Nieznana starsza konfiguracja zakłócająca działanie bibliotek Spring Boot.
- Fasola bez superklasy.
- AKT 4 Ostateczne spotkanie – pełna regresja.
- Problemy z konfiguracją Springa XML.
- Problemy z wydajnością menedżera transakcji.
- Opóźnienia kwarcowe.
- Długo i szczęśliwie
AKT 1
(Nie)spodziewana podróż – wprowadzenie
Notka autora
Wiele działań odbywało się równolegle. Wiele z nich było znacznie bardziej skomplikowanych niż opisano tutaj. Ze względu na historię i dla ułatwienia czytania mogą pojawić się drobne zakłócenia w osi czasu.
W tym miejscu chciałbym podziękować wszystkim osobom, które pomogły mi dokończyć ten artykuł – głównie członkom zespołu GFT i liderom rodziny GFT. Przede wszystkim jednak chciałbym podziękować Arkowi Gasińskiemu za szczegółową recenzję tego tekstu i mnóstwo cierpliwości, jaką miał do mnie.
- Kierownik projektu: Marcin Radzki
- Main Dev: Krzysztof Skrzypiński
- QA: Agata Kołuda
- Devs: Roman Baranov, Damian Kotynia, Łukasz Kotyński
Nasz projekt – ETF Manager – istnieje od zawsze. Przynajmniej dłużej niż większość z nas pracuje tutaj – w GFT. Nawet dłużej, niż trwa moje doświadczenie zawodowe. Na pierwszy rzut oka bycie tutaj przypomina przebywanie na wygnaniu (co nie jest na wielu poziomach – za sprawą innych członków zespołu, obecnych i byłych).
Świat menedżerów ETF
Menedżer ETF polega na łączeniu banków inwestycyjnych z animatorem rynku ETF i ich firmą świadczącą usługi finansowe. . Dzięki temu ETFM nie musi być najszybszy. Ale musi być niezawodny.
Ponieważ projekt trwa wiecznie, większość z nas dołączyła do niego w różnym czasie. Nasz obecny lider, Marcin, ma najdłuższe doświadczenie projektowe. Wszystko, co się tutaj dzieje, przechodzi przez niego. Każda podjęta decyzja musi zostać przez niego zatwierdzona.
Następny jest Krzysztof. Zajmuje drugie miejsce pod względem stażu pracy. Jego zadaniem jest dotrzymywanie kroku harmonogramom i upewnianie się, że wszystko jest gotowe na czas. I nie dzień później. Kiedy pojawia się wyzwanie do rozwiązania lub problem produkcyjny, on jest pierwszym, który podejmuje działanie.
Ostatnią ze „starej załogi” jest Agata. Musi dopilnować, aby nasza Jira nigdy nie była pusta. Za każdym razem, gdy kończymy nasze zadania, ona szuka luk.
Marcin, Krzysztof i Agata współpracują z Menedżerem ETF już od około siedmiu lat. My – ja, Roman i Damian – jesteśmy „nową załogą” – świeżą krwią tego projektu. Jesteśmy tu od niecałych trzech lat. Naszym zadaniem jest pomóc w utrzymaniu tego projektu i upewnić się, że nie rdzewieje.
Nasza (nie)oczekiwana podróż
W miarę jak nasz projekt dojrzewa, ładniejszy sposób powiedzenia staje się dziedzictwem;), musimy zachować czujność i skupić się na przestarzałych technologiach. Częścią naszej podróży jest usuwanie starych i niepewnych rzeczy i zaproponowanie czegoś bardziej modnego (jazzowego?).
Ale nie tylko bezpieczeństwo może skłonić Cię do zastąpienia niektórych starszych. Stara i nadmiernie skomplikowana technologia kosztuje. Ona (poprzednia wersja systemu) została stworzona jako rzecz nie najłatwiejsza w utrzymaniu – co na dłuższą metę jest też wydatkiem. To właśnie skłoniło nas do podjęcia ważnej decyzji: zastąpimy JBossa Spring Boot! Szalone, prawda?!
AKT 2
Wygaszenie migracji – pierwsze małe migracje mikroserwisów
Przejdź na Spring Boot, mówili… Ale jak zacząć? Migracja z samodzielnego serwera JBoss do wbudowanego serwera Tomcat nie brzmi „aż tak” źle. Z drugiej strony można na to spojrzeć tak: „jak zmienić fundamenty domu?” Wtedy wygląda to „trochę” bardziej skomplikowanie. Jak więc zacząć wprowadzać taką „fundamentalną” zmianę?
Na szczęście dla nas ETFManager ma w jakiś sposób mieszaną architekturę. Posiada moduł podstawowy – będący średniej wielkości monolitem – otoczony kilkoma mikroserwisami odpowiedzialnymi za komunikację ze światem zewnętrznym. Wszystko luźno połączone za pośrednictwem brokera przesyłania komunikatów AMQ.
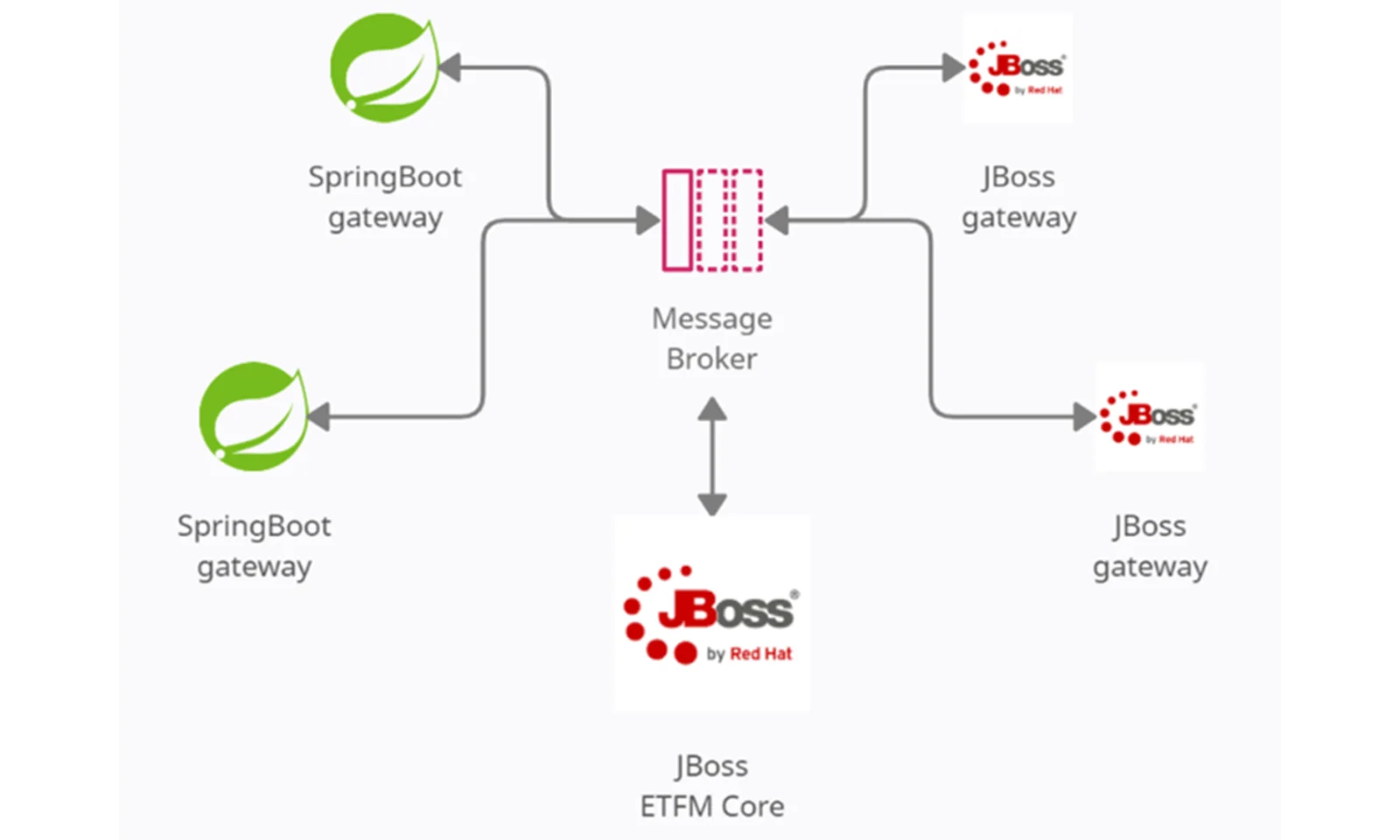
Większość naszych bram korzysta już ze Spring Boot. Z drugiej strony dwóch z nich nadal pracuje nad JBossem. Ponieważ bramy są stosunkowo prostymi aplikacjami, wybraliśmy je do naszego ośrodka eksperymentalnego.
Konfiguracja wstępna
Ponieważ większość naszych bram była już napisana w Spring Boot, zdecydowaliśmy się na replikację struktury plików i konfiguracji w niezmienionej postaci. Stworzyliśmy dodatkowy katalog, który zawierał wszystkie właściwości związane ze środowiskiem, konfiguracje rejestrowania i uruchamiane skrypty wsadowe/powłokowe.
- wejście
- odl
- wspólne.właściwości aplikacji
- właściwości dewelopera aplikacji
- właściwości przedprodukcyjne aplikacji
- właściwości produktu aplikacji
- właściwości aplikacji-sit
- właściwości obsługi aplikacji
- właściwości aplikacji-uat
- jeden
- cii
- xml
- logback-dev.xml
- źródło
- … kod aplikacji
- kompilacja.gradle
- odl
dist to katalog domowy aplikacji. Wewnątrz znajdują się pliki konfiguracyjne
- common, który zawiera konfigurację współdzieloną
- konfiguracje specyficzne dla środowiska
Ponieważ wszystkie nasze środowiska, poza deweloperskim, zapisują logi na tym samym serwerze Kibana, mamy dwie konfiguracje logowania:
- dev – dla rozwoju lokalnego
- wspólne – dla każdego odległego środowiska.
Aby ułatwić uruchomienie, utworzono dwa pliki skryptów, tj. bat i sh. Zawierają proste użycie i trochę JAVA_OPTS.
Zachowanie tej konfiguracji z kodem nie wydaje się najlepszym pomysłem, ale traktujemy to jako etap przejściowy przed dokowaniem (konteneryzacją) aplikacji. Na razie wolimy nadal działać w ujednolicony sposób ze starymi aplikacjami.
Po zastosowaniu zmian w konfiguracji środowiska wykonawczego przeszliśmy do zależności Gradle. Dodaliśmy startery do rozruchu wiosennego i usunęliśmy niepotrzebne JBoss lub zduplikowane startery Spring. Cel WAR został zastąpiony za pomocą wtyczki Spring Boot Gradle przez wykonywalny plik JAR. Dodano niestandardowe zadanie spakowania i spakowania naszego katalogu `dist`. Stara konfiguracja zależności „kompiluj” została zastąpiona nową „implementacją”. Dodano klasyczną metodę `SpringApplication.run()` i voila! Robimy pierwszą jazdę próbną!
JBoss świadczył usługi
Nie. Oczywiście nie było to takie proste. Uruchomienie aplikacji ujawniło kilka brakujących definicji fasoli. Wszystkie bramy zostały podłączone do usług zewnętrznych, takich jak DB lub Message Broker. Gdy aplikacje działały na JBoss, Enterprise Server udostępniał konfiguracje umożliwiające łączenie się z tymi usługami poprzez JNDI. Było tak oczywiste, że te usługi są świadczone, że prawie zapomnieliśmy o ich istnieniu.
Na szczęście przepisanie ich nie było takie trudne:
- najpierw musieliśmy znaleźć wszystkie zależności JNDI wstrzyknięte do aplikacji
- znaleźliśmy je w konfiguracji JBoss po zastrzykach JNDI, a następnie zwalidowaliśmy ich użycie w aplikacji po nazwach JNDI
- następnie musieliśmy zapewnić nasze fabryki połączeń:
- Atomikos dla DB
- RedHat Artemis dla AMQ 7
- Na koniec musieliśmy wszystko połączyć w całość za pośrednictwem naszego menadżera transakcji – tak jak poprzednio zapewnił JBoss
Przy pomocy oprogramowania Atomikos i Spring Data o otwartym kodzie źródłowym rozwiązano to małe wyzwanie i pomyślnie nawiązano połączenia z brokerami przesyłania wiadomości.
Starszy kod zależny od JNDI
Jednak, jak wspomniałem na początku, nasza aplikacja jest dość przestarzała. Udostępnienie aplikacji źródeł danych to jedno. Inną sprawą jest udostępnianie za ich pomocą zewnętrznych (starszych) bibliotek. Jedna z bramek korzysta z komunikacji Autex FIX. . . I tylko poprzez JNDI. Szybkie wyszukiwanie… teoretycznie nie stanowi to problemu. Tomcat może zapewnić JNDI.
Dokonaliśmy konfiguracji Java z ładnym i czystym ładowaniem komponentów bean do kontekstu JNDI. Pojedyncze źródło danych było używane z JNDI i innymi komponentami bean. Wszyscy szczęśliwi, zrobiliśmy pierwszą rundę testową. Po kilku nieudanych próbach Roman odkrył, że… Kontekst JNDI Tomcata w Spring Boot jest czyszczony po inicjalizacji kontekstu. Nie znaleziono bezpośredniego rozwiązania. Tylko po to, aby ponownie napisać cały kod zależny od JNDI na coś bardziej aktualnego.
Po jeszcze bardziej szczegółowych poszukiwaniach i wielu łzach później, głęboko w otchłani internetu, znaleźliśmy to. Dołączany osadzony kontekst JNDI. Niestety, nasz święty Graal okazał się częściowo przestarzały. Po raz kolejny odważny Roman uratował sytuację, wskakując do Spring Code i udostępniając nasz zamiennik przekreślonej treści. Skończyło się na implementacji SimpleNamingContextBuilder i małego kontekstu JNDI:
- @Fasola
- @DependsOn( „Menedżer transakcji” )
- publiczny javax.naming.Context początkowyJNDIContext(
- Źródło danychŹródło danych,
- Menedżer transakcji użytkownika. Menedżer transakcji użytkownika
- ) zgłasza wyjątek NamingException {
- Konstruktor EtfmSimpleNamingContextBuilder = nowy EtfmSimpleNamingContextBuilder();
- konstruktor.aktywuj();
- JndiTemplate jndiTemplate = nowy JndiTemplate();
- javax.naming.Context ctx = jndiTemplate.getContext();
- ctx.bind( „java:comp/env/cust/ETFMDatasourceIM“, źródło danych );
- ctx.bind( „java:/TransactionManager”, userTransactionManager );
- ctx.bind( „Java:comp/env/cust/UserTransaction”, userTransactionManager );
- zwróć ctx;
- }
Zadziałało! Hacky czy nie, przełożyliśmy ponowne napisanie jednej starszej biblioteki, oszczędzając trochę czasu na nadchodzącą bitwę…
AKT 3
Wielka bitwa – migracja głównego monolitu
Po tych kilku udanych potyczkach rozpoczęliśmy przygotowania do bitwy głównej – modułu rdzenia (monolitu) ETF Managera. Ostatnie zwycięstwa utwierdziły nas w przekonaniu o naszych mocnych stronach. Jednak skala zastosowania wzrosła dramatycznie. Licząc tylko wagę kodu Java, było to od jednego do dwudziestu. Dlatego nogi nam się trzęsły. Ale nasze serca były pełne wiary.
Czyszczenie konfiguracji
Nauczeni poprzednimi walkami, zaczęliśmy od stworzenia konfiguracji i przepisania zasobów dostarczonych przez JBossa. Ponieważ zyskaliśmy trochę czasu podczas ponownego pisania bramek, Damian przeniósł wszystkie możliwe konfiguracje z XML-ów na Javę, czyszcząc ją tak bardzo, jak to możliwe. Później dowiedzieliśmy się, że powodowało to pewne problemy, ale nadal była to uczciwa cena za czystą i zwięzłą konfigurację.
Zarządzanie hasłami
Pierwsza ściana uderzyła w nas jeszcze przed pierwszym startem. Jeszcze zanim zdążyliśmy się rozgrzać, dotarliśmy do pierwszej ściany – zarządzanie hasłami. Do tej pory korzystaliśmy z JBoss Vault. Likwidacja serwera JBoss zmusiła nas do zakupu nowego skarbca. Szybkie dochodzenie – brak dostępnych skarbców osadzonych. Najbliższym możliwym rozwiązaniem jest HashiCorp Vault. Chcieliśmy jednak uprościć naszą aplikację i nie dodawać kolejnych zależności, którymi będziemy się zajmować. Zapytaliśmy klienta, czy moglibyśmy skorzystać z jego globalnego skarbca. Okazało się, że była to preferowana opcja zgodnie z obowiązującymi zasadami.
Rozpoczęliśmy przygotowania do migracji do repozytorium. Zrobiliśmy PoC. Złożyliśmy kilka próśb o dostęp do skarbca klienta. Odbyło się kilka spotkań z zespołem klienta… i utknęliśmy. Przez kilka miesięcy nic się nie działo. Firma klienta jest na tyle duża i trzeba było w nią zaangażować tak wiele zespołów, że nasza prośba utknęła. A data migracji była coraz bliżej. Na szczęście Roman ponownie uratował nam dzień, udostępniając nam sklep z kluczami Java. Ostatecznie zostało ono zatwierdzone przez klienta jako rozwiązanie tymczasowe w oczekiwaniu na dostęp do skarbca klienta.
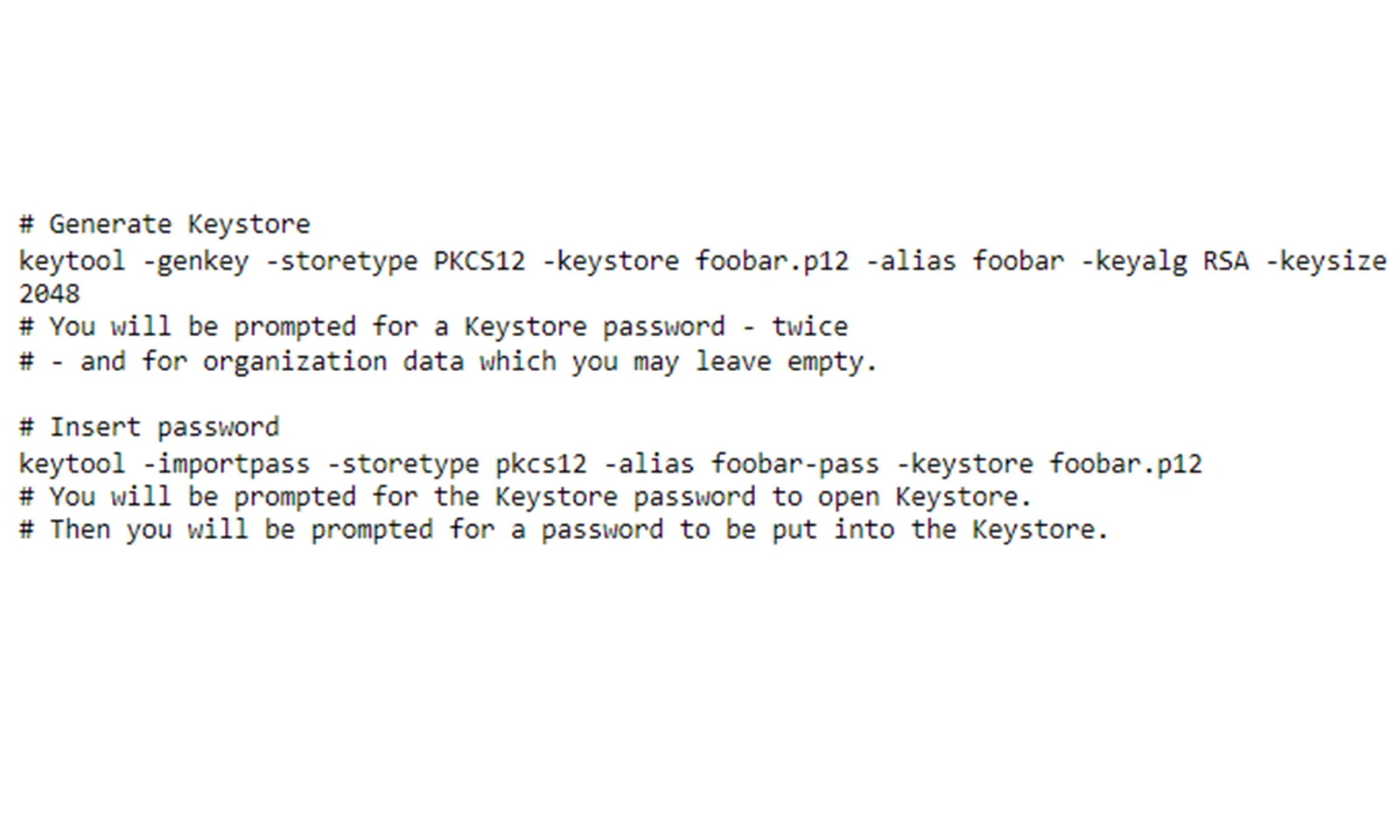
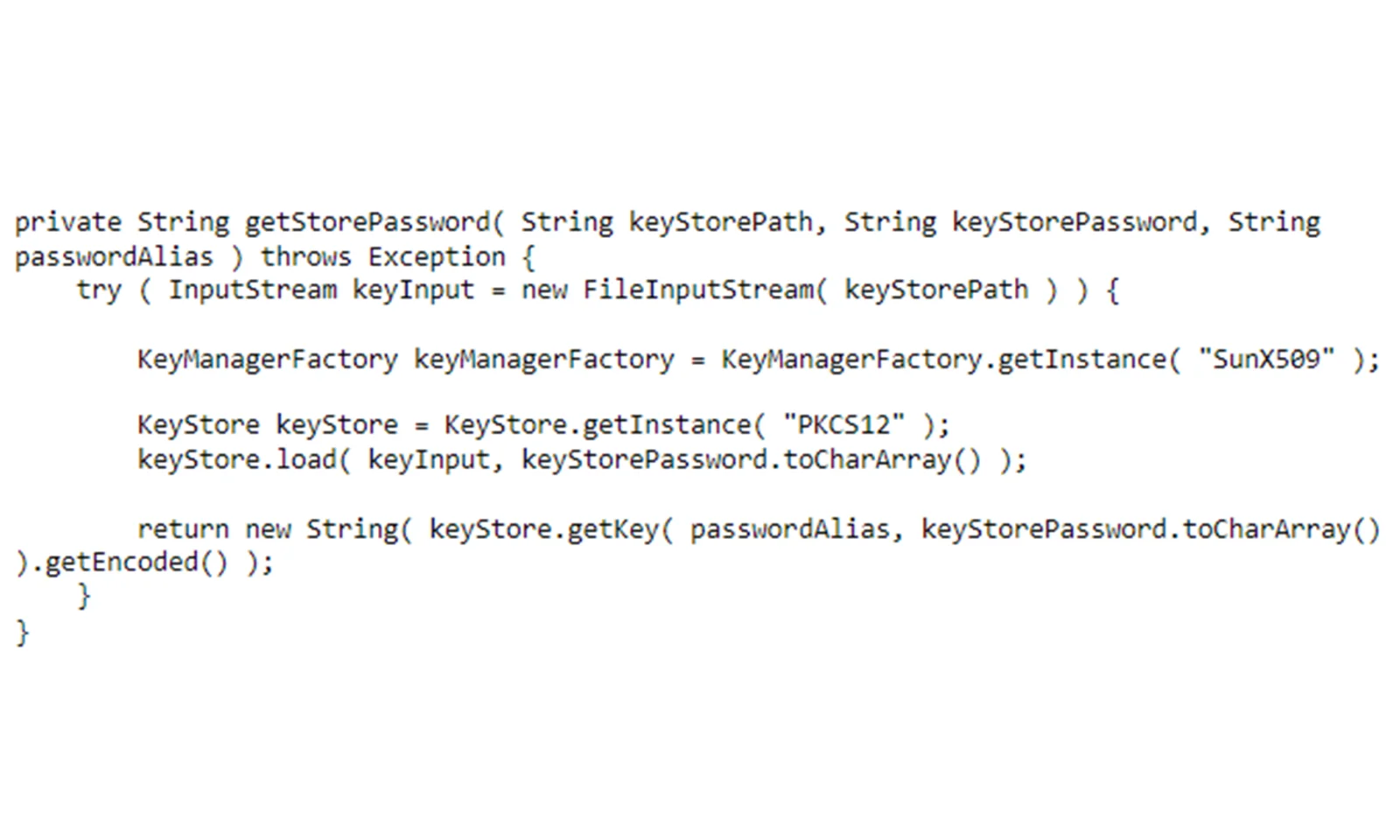

Nieznana starsza konfiguracja zakłócająca działanie bibliotek Spring Boot
Pierwszy bieg i kolejna ściana. Aplikacja nie uruchamiała się. Żeby było jeszcze dziwniej, podczas inicjalizacji klasy Spring pojawił się błąd. Wiosna walczyła sama ze sobą, a my nie wiedzieliśmy dlaczego.
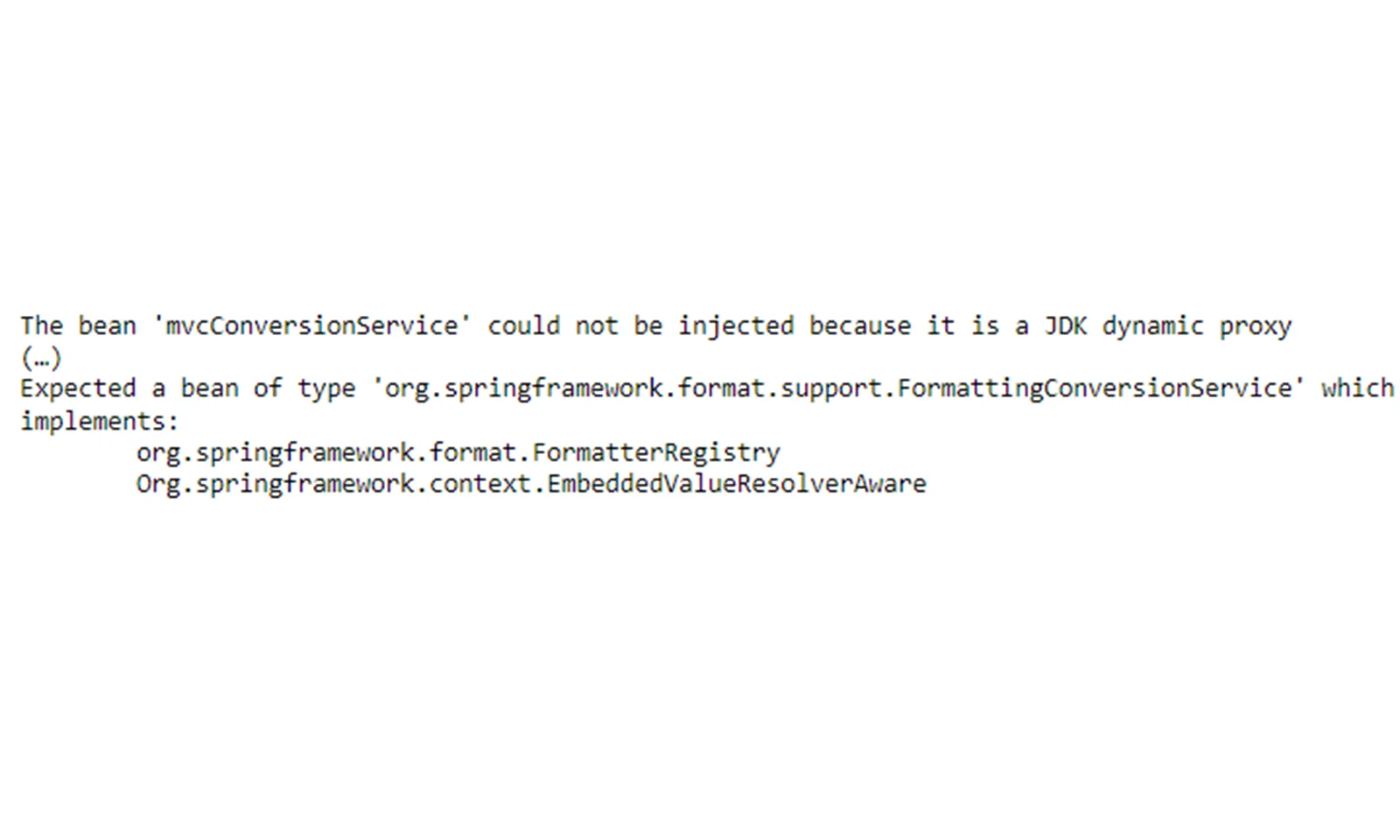
Dokonaliśmy konfiguracji sieciowej zarówno w stylu Spring Boot, jak i w czystym Springu, i nadal – tworzyliśmy błąd proxy. W przypadku klasy bez interfejsu należy wygenerować serwer proxy CGLIB, ale z jakiegoś powodu wymuszony jest czysty serwer proxy JDK. Co najlepsze – internet milczy. Czuliśmy się jak dzieci błądzące we mgle.
Wiele godzin, jeszcze więcej filiżanek kawy później, kilka rozmów z Big Headami z GFT (wielkie podziękowania dla Piotra Gwiazdy) i trochę inżynierii wstecznej Springa doprowadziło nas do dostosowania konfiguracji Springa. Z jakiegoś powodu oryginalna klasa Springa „WebMvcConfigurationSupport” nie działała poprawnie z naszą aplikacją. Musieliśmy po nim odziedziczyć i zastąpić niektóre ustawienia domyślne (proxy).

Ale to nie był jedyny problem związany z wiosną.
Fasola bez superklasy
Jeden problem rozwiązany sprawił, że w twarz uderzył nas kolejny.
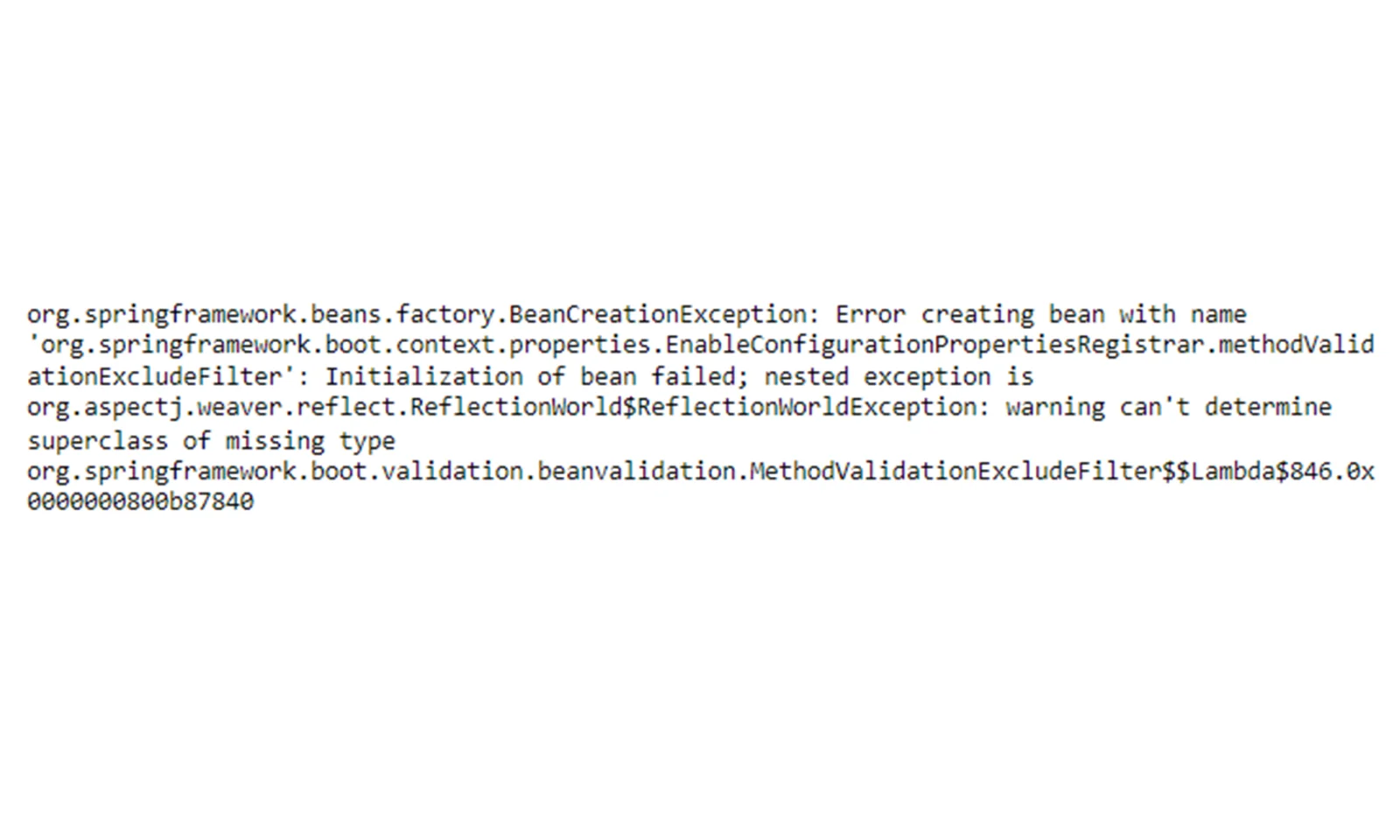
Wiosna po raz kolejny zdecydowała się zawieść na własnym kodzie. Utworzenie zupełnie bezsensownego dla nas fasoli spowodowało błąd inicjalizacji aplikacji. Prosta konstrukcja Lambda zawinięta w nieco bardziej złożony BeanDefinitionBuilder nie powiodła się. Ale dlaczego?

Odpowiedź na to pytanie jest stosunkowo prosta. Wyrażenie Lambda nie jest w pełni kwalifikowaną klasą anonimową. Przez to w świecie refleksyjnym mieliśmy problem z uzyskaniem jego interfejsu. Były próby ominięcia tego problemu, ale niestety nie działa to z Javą wyższą niż 9 ( https://github.com/spring-projects/spring-framework/issues/17130 ). Na szczęście dla nas znaleźliśmy akceptowalne rozwiązanie, zastępując oryginalny Spring Bean:
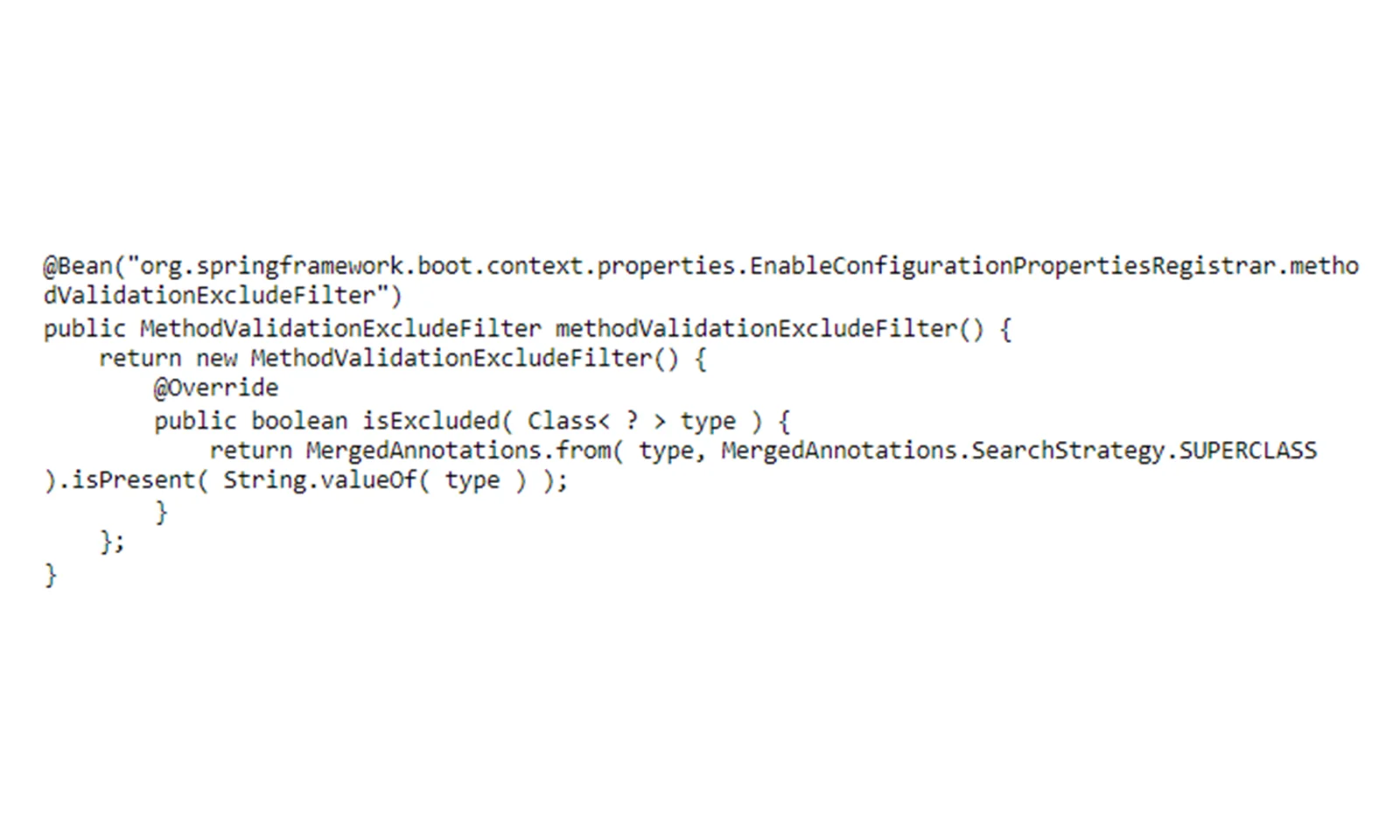
Wreszcie w logach pojawił się długo oczekiwany komunikat ` Uruchomiono aplikację Etfm w… `! Ale to nie był koniec, a raczej krótka cisza przed ostatnią burzą.
AKT 4
Spotkanie końcowe – pełne testy regresyjne
Po kilku poprawkach tu i ówdzie, aplikacja była dla Niej gotowa. Agata – nasza QA – otrzymała pakiet i rozpoczęła pełną regresję. Każdy fragment kodu został przetestowany. Każda ścieżka, przepływ, każdy proces…
Ale przede wszystkim – cała ta migracja nie odbyła się tak spontanicznie, jak mogłoby się wydawać na pierwszy rzut oka. Aplikacja jest w pewnym sensie starsza i ma całkiem sporo testów jednostkowych. Ponieważ nasze zajęcia niewiele się zmieniły, te testy nie były zbyt pomocne. Naszą drugą zaletą był stosunkowo duży zestaw testów integracyjnych i całkiem niezawodny runbook do ważnych prac ręcznych. Z takim garniturem rozpoczęliśmy migrację pewni, że w najgorszym przypadku wrócimy do punktu wyjścia. Awaria produkcyjna nie była brana pod uwagę jako opcja.
Problemy z konfiguracją Springa XML
Większość funkcji działała zgodnie z oczekiwaniami, ale pojawiły się pewne zakłócenia. Wstrzyknięto niewłaściwe ziarna w nieoczekiwanych miejscach. Dokonano błędnych połączeń poprzez niewłaściwe źródła danych. Sprawdzaliśmy kod wiele razy i wszystko wyglądało dobrze. Nie było miejsca, gdzie coś mogłoby pójść nie tak. Ale nadal coś było nie tak. Nasza konfiguracja nie działała zgodnie z oczekiwaniami, ale zaczęła żyć własnym życiem.
Po kilku godzinach debugowania i porównywaniu nowego kodu ze starym znaleźliśmy go. Jak wspomniałem wcześniej, ponownie napisaliśmy konfigurację XML w Javie. Okazało się, że XML może obsłużyć znacznie więcej niż Java. Niewiele klas konfiguracyjnych i ustawiaczy automatycznego okablowania korzystało z niewłaściwych typów klas (ogólnych?). Podczas gdy XML po cichu akceptował je i obsługiwał zgodnie z życzeniem twórcy, konfiguracja Java sprzeciwiała się niewłaściwej konfiguracji. I niestety, zamiast podanych, zastosowano wartości domyślne… CICHY!



Ze względu na problem z typem nie mogliśmy rozwiązać tego problemu za pomocą prostego @Qualifier, ponieważ wykryto by niezgodność typu.
Wykrycie problemu i naprawienie powyższego przykładu jest dość proste. Jednak w rzeczywistym scenariuszu z wieloma podobnymi komponentami bean uświadomienie sobie, co się dzieje, może zająć trochę czasu. Ponadto zagnieżdżanie ziaren może znacznie utrudnić znajdowanie problemów, ponieważ niewłaściwy typ może być propagowany przez wiele zagnieżdżonych poziomów wywołania. Mimo to… lepiej zdawać sobie sprawę z takich usterek.
Problemy z wydajnością menedżera transakcji
W miarę jak nasza aplikacja stawała się coraz bardziej stabilna, pojawił się nowy wróg – problemy z wydajnością. Po pierwsze, logowanie do aplikacji – pod załadowaną aktualnymi danymi bazę danych – stało się zadaniem dość czasochłonnym. Po drugie, w JBoss wykonanie wszystkich zadań w tle zwykle zajmowało kilka sekund. To samo w Spring Boot może zająć ponad dwadzieścia sekund.
Nasze pierwsze kroki podczas badania tych problemów z wydajnością skłoniły nas do sprawdzenia, co działo się podczas uruchamiania. Szybkie sprawdzenie procesu uruchamiania i stało się jasne, że dla setek aktywnych transakcji użytkowników aplikacja wykonywała tysiące zapytań do bazy danych. A mimo to – JBoss po prostu spisał się lepiej.
Zaczęliśmy sprawdzać konfiguracje zarówno źródeł danych, jak i pul połączeń. Napisano kilka testów dla różnych wartości. Ale wyniki nie były zadowalające. Zdobycie kilku sekund nie może się równać z szybkością JBossa. Ostatecznie zdecydowaliśmy się zoptymalizować kod ładowania. Spełniło swoje zadanie, ale i tak czuliśmy się trochę rozczarowani. Czy był to problem z konfiguracją? A może JBoss wykonał swoją pracę lepiej niż open-source'owy Atomikos?
Opóźnienia kwarcowe
Jednak problemy z ładowaniem aplikacji nie były jedynymi problemami związanymi z wydajnością. Niektóre procesy naszej aplikacji działają w tle i są uruchamiane przez harmonogram Quartz. Jednak od czasu do czasu niektóre z tych procesów trzeba uruchomić ręcznie.
Ręczne uruchomienie akcji na JBossie zadziałało natychmiast. Wykonanie tego samego w Spring Boot spowodowało około 20 do 30 sekund opóźnienia. Ale dlaczego? Z naszej perspektywy wydawało się, że „nic” nie trwało zbyt długo. W bazie kodu, która nie była nasza, miała miejsce długa przerwa. Znalezienie zewnętrznego kodu powodującego tę przerwę również było dla nas niemożliwe.
Oczywiście Google był naszym pierwszym strzałem. Szybkie wyszukiwanie nie znalazło rozwiązania. Jednak zagłębiając się coraz głębiej, odkryliśmy, że usunięcie @Transactional z naszej usługi ręcznego wyzwalania spełniło swoje zadanie. Mieliśmy więc wybór: zaakceptować opóźnienie lub wykonać wiele operacji w oddzielnych transakcjach.
Na szczęście dla nas czas nie był krytyczny, więc wybrano pierwszą opcję, ale sprawa wciąż czeka na rozwiązanie. Czy jest to związane z zarządzaniem transakcjami Spring Boot, czy może Atomikos? Czy będziemy w stanie dostroić to zachowanie? A może jest tak, że otwarte wersje bibliotek, z których korzystamy, po prostu działają gorzej niż ich płatne odpowiedniki?
Długo i szczęśliwie
Oczywiście ta historia nie wyczerpuje wszystkich problemów, z jakimi się spotkaliśmy. Po drodze znaleźliśmy wiele innych mniejszych problemów, o których prawdopodobnie nie warto wspominać w tym artykule. Poza tym Krzysztof i Marcin nie tylko pomogli nam podczas migracji, ale co najważniejsze, świetnie się spisali, chroniąc nas przed wszelkimi wpływami zewnętrznymi. Wzięli na swoje barki odpowiedzialność za negocjacje z klientem, skanowanie bezpieczeństwa i wszelkie inne doraźne problemy.
Dalsze testy ujawniły kilka innych drobnych problemów z wydajnością połączeń DB. Zastosowaliśmy pewne poprawki, ale i tak od czasu do czasu przypominają nam o sobie w różnych miejscach kodu. Prawdopodobnie system transakcyjny JBoss działa po prostu lepiej niż Open Source Atomikos. A może nasza konfiguracja Atomikosa nie została dostosowana tak dobrze, jak mogła.
Mimo to udało nam się. Dociskaliśmy do końca. Wycofaliśmy naszego JBossa z całego jego ogromnego potencjału, ale równie ogromnego rozmiaru i kosztów infrastruktury. I zastąpiliśmy go lekkim i darmowym Spring Bootem.
Czy było warto? Z jednej strony straciliśmy komercyjne wsparcie Red Hat i niesamowicie wyposażony serwer Java Enterprise. Z drugiej strony udało nam się obciąć niemałe koszty i usamodzielnić naszą aplikację, co było jednym z kluczowych kroków w stronę przygotowania jej do pracy w chmurze. Na krótką metę było to mnóstwo pracy, która nie wnosiła dla klienta żadnej wartości biznesowej. W dłuższej perspektywie pozwoliło to klientowi zaoszczędzić sporo kosztów i pozwoliło ewoluować projektowi w kierunku ery przetwarzania w chmurze. A to na pewno przyda się w nadchodzących latach.
Sama podróż była trudna, ale dała nam dużo doświadczenia na temat serwerów aplikacji dla przedsiębiorstw, a także samodzielnych serwerów Java.




